
Earlier today, Facebook experienced a 6 hour long outage that took out several services including Facebook, WhatsApp and Instagram. This is the not the first time that Facebook has had a significant outage, in 2015, Instagram’s TLS certificate expired, a software bug caused an outage in 2016 and in 2019, a server misconfiguration caused a massive outage that was only fully resolved 24 hours later.
The internet is a network of networks, which require the use of protocols like Border Gateway Protocol (BGP) so that these networks can tell other networks to how to route traffic to and from them. Providers use BGP to determine which networks their traffic is routed through taking into account cost and speed.
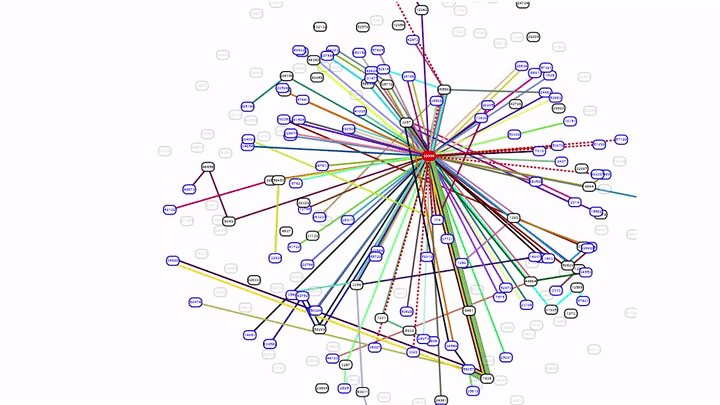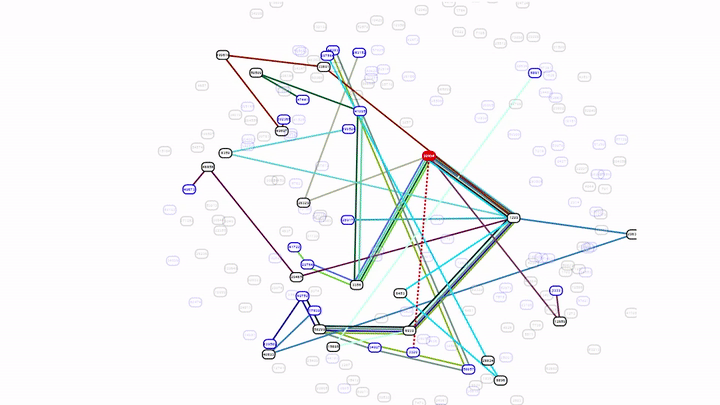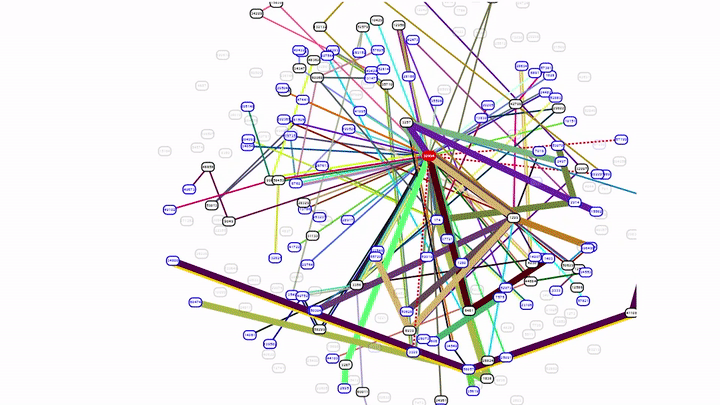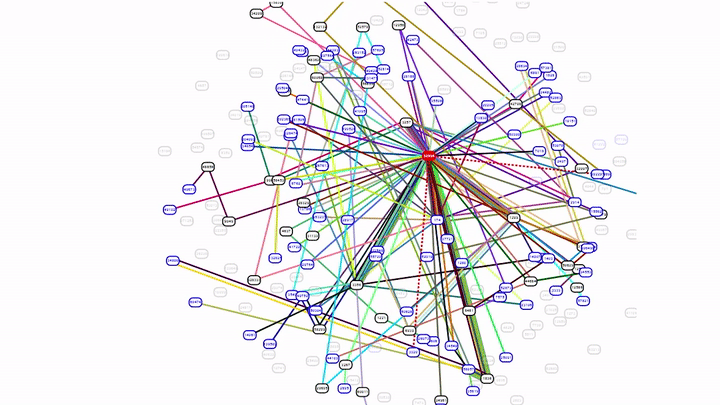
The root cause of this outage was a BGP mishap that started at roughly 15:30 UTC when the first set of BGP announcements for various prefixes were made, at 15:39 UTC a series of BGP announcements were observed including various route withdrawal requests and at 15:42, a large amount of BGP route withdrawals took place. BGP withdrawals effectively withdraw an announced route that was previously made.
Facebook has 2 ASN networks (AS32934 and AS63293) which have a combined total of 209 IPv4 prefixes and 305 IPv6 prefixes which cover a total of 158 208 IP addresses. Both ASNs were affected by this announcement and affected internal and external systems of services including Facebook, WhatsApp, and Instagram. Most notably Facebook’s DNS servers which serve all 3 services was also affected as the BGP route for the prefix that houses this critical piece of infrastructure was withdrawn. As a result, important core, and internal services were not reachable. This meant that any requests internally or externally would fail as DNS is a core building block of network infrastructure.
Shortly after the start of the outage, a member of the Facebook infrastructure team posted on Reddit that:
There are people now trying to gain access to the peering routers to implement fixes, but the people with physical access is separate from the people with knowledge of how to actually authenticate to the systems and people who know what to actually do, so there is now a logistical challenge with getting all that knowledge unified (sic).
In the animation below, you can see the initial BGP announcements for a small set of prefixes with some withdrawals made at 15:39 UTC followed by the large amount of withdrawals at 15:42 UTC. At 17:14 UTC, routes for a subset of prefixes were re-announced. At 21:19 UTC, a large number of prefixes were re-announced which re-established connectivity to the internet and by 22:00 UTC all services appeared to be operating normally.
During the outage, Facebook’s official status page at status.fb.com and the homepage of the registrar that Facebook uses was also not available. With no DNS resolution in place, no email could be sent or delivered, and internal tools were not usable. There were reports of Facebook employees that were unable to access the office as the access system was also affected. Due to the lack of DNS resolution, some registrars like GoDaddy displayed that Facebook.com was for sale which is a quirk in the way that domain tools handle this situation.
Lessons to be learned:
While we will have to wait for Facebook’s official post-mortem, it is certainly clear that the recovery of this situation was probably quite challenging and was exacerbated by the fact that the tools needed to fix the issue were unreachable by the respective engineers. Engineers needed to gain physical access to the peering routers in data centers in order to authenticate to the systems that could resolve this issue. Restarting a large distributed system is very complicated which is further complicated if systems need to bootstrap from other systems that may not be available at the time that they are restarted.
All IT teams, especially those in charge of large complex networks should regularly run incident response tests to ensure that if such events occur, they are equipped to deal with them. These tests should also ensure that the required break glass processes are in place to deal with unusual events such as what happens when physical access control systems are not working. In 2019, a GPS time epoch roll-over occurred and some enterprises whose NTP sources relied on GPS time found themselves in a precarious situation when the time rolled back to 1980 and all their certificates stopped working.
In the past, issues with BGP have generally centered around a single bad route announcement or BGP hijacking which is enabled by the trust relationships that network operators have with each other. In 2017, a Russian controlled telco performed a BGP hijack on MasterCard, Visa and 2 dozen financial services and in 2018, hackers performed a BGP hijack of Amazon’s DNS to steal cryptocurrency. The issue of BGP hijacking can be solved with Resource Public Key Infrastructure (RPKI), however not all ISPs are RPKI compliant.
Event timeline:
- 15:31 – First BGP announcement is observed on several prefixes
- 15:39 – Several announcements were made including route withdrawal requests
- 15:42 – A significant amount of BGP withdrawals requests are announced which also include prefixes of the DNS servers
- 17:14 – The subset of prefixes are being re-announced to external networks
- 21:19 – Many announcements are made to bring services online
- 21:25 – DNS resolution is working but Facebook and WhatsApp are still inaccessible
- 21:45 – WhatsApp starts sending notifications
- 22:00 – All services appear to be restored
If you are interested in BGP, Facebook did a Usenix talk earlier this year speaking about how they do BGP.
This is a developing story and will be updated as new details emerge…
